Il y a 19 heures
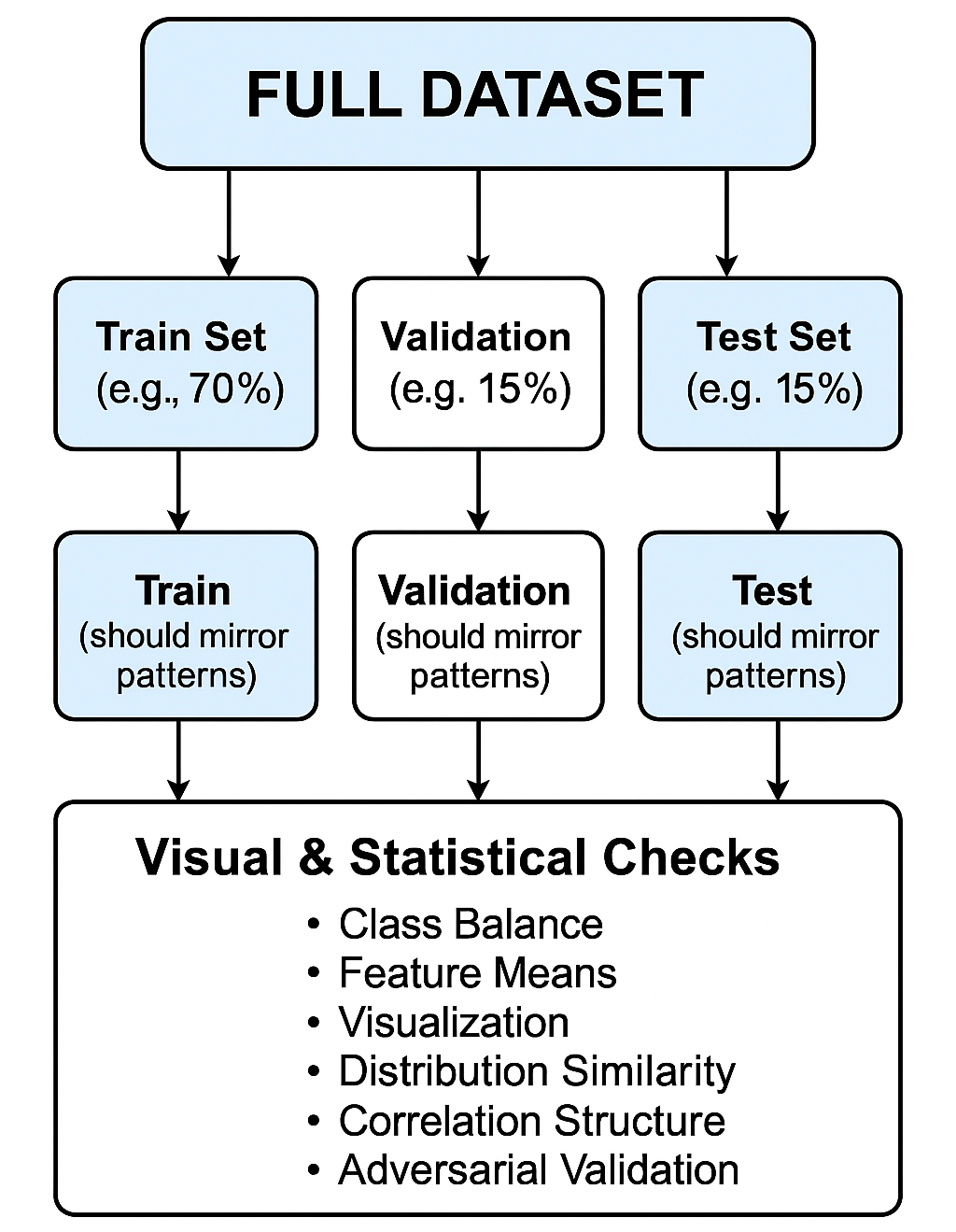
Contexte: Assurer le fait que les divisions de train, de contrôle et de test sont un ensemble de données entier, est crucial pour l’apprentissage automatique fiable.
Problème: Si le fractionnement des données ne peut pas corriger les échantillons de base de l’ensemble de données d’origine, l’évaluation de l’efficacité du modèle peut être peu fiable et les modèles peuvent ne pas résumer la production.
Approche: Nous considérons et faisons preuve d’indicateurs pratiques, y compris l’équilibre de la classe, les statistiques descriptives, les tests de distribution (par exemple, KS-Test, Wasstein Diste), la comparaison de la matrice de corrélation, la visualisation et la vérification de l’ennemi pour la comparaison systématique de la division avec l’ensemble de données complet.
Résultats: Appliqués à l’ensemble de données de bibliothèque standard, les vérifications visuelles et statistiques indiquent la forte représentativité de toutes les divisions. Cependant, la vérification de la compétition a montré un préjugé caché potentiel, soulignant l’importance d’utiliser plusieurs indicateurs supplémentaires.
Conclusion: Une analyse complète utilisant des méthodes statistiques et du modèle est importante pour vérifier l’intégrité des données et la création de modèles fiables et généralisant l’apprentissage automatique.
Mots clés: Division des données de représentativité; Vérifier l’apprentissage automatique; Métriques de distribution des données; Analyse de la fusion de la vérification du train; Vérifier la compétition
Game Center
Game News
Review Film
Rumus Matematika
Anime Batch
Berita Terkini
Berita Terkini
Berita Terkini
Berita Terkini
review anime